BrainTalker: Low-Resource Brain-to-Speech Synthesis with Transfer Learning using Wav2Vec 2.0
Submitted to IEEE BHI 2023
Authors
Miseul Kim, Zhenyu Piao, Jihyun Lee and Hong-Goo Kang†
Github code
Proposed Method
Decoding spoken speech from neural activity in the brain is a fast-emerging research topic, as it could enable communication for people who have difficulties with producin audible speech. For this task, electrocorticography (ECoG) is a common method for recording brain activity with high temporal resolution and high spatial precision. However, due to the risky surgical procedure required for obtaining ECoG recordings, relatively little of this data has been collected, and the amount is insufficient to train a neural network-based Brain-to-Speech (BTS) system. To address this problem, we propose BrainTalker—a novel BTS framework that generates intelligible spoken speech from ECoG signals under extremely low-resource scenarios. We apply a transfer learning approach utilizing a pre-trained self-supervised model, Wav2Vec 2.0. Specifically, we train an encoder module to map ECoG signals to latent embeddings that match Wav2Vec 2.0 representations of the corresponding spoken speech. These embeddings are then transformed into mel-spectrograms using stacked convolutional and transformer-based layers, which are fed into a neural vocoder to synthesize speech waveform. Experimental results demonstrate our proposed framework achieves outstanding performance in terms of subjective and objective metrics, includinga Pearson correlation coefficient of 0.9 between generated and ground truth mel-spectrograms. We share publicly available Demos and Code.
Seen samples
| GT Spectrogram |
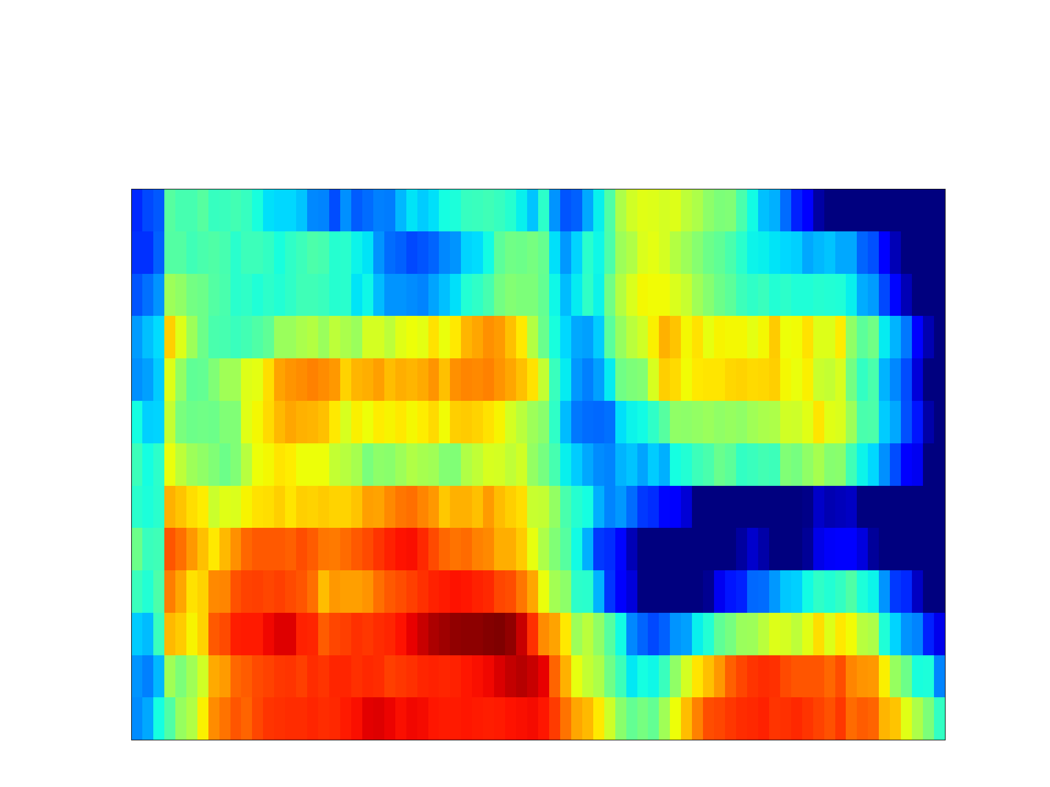
|
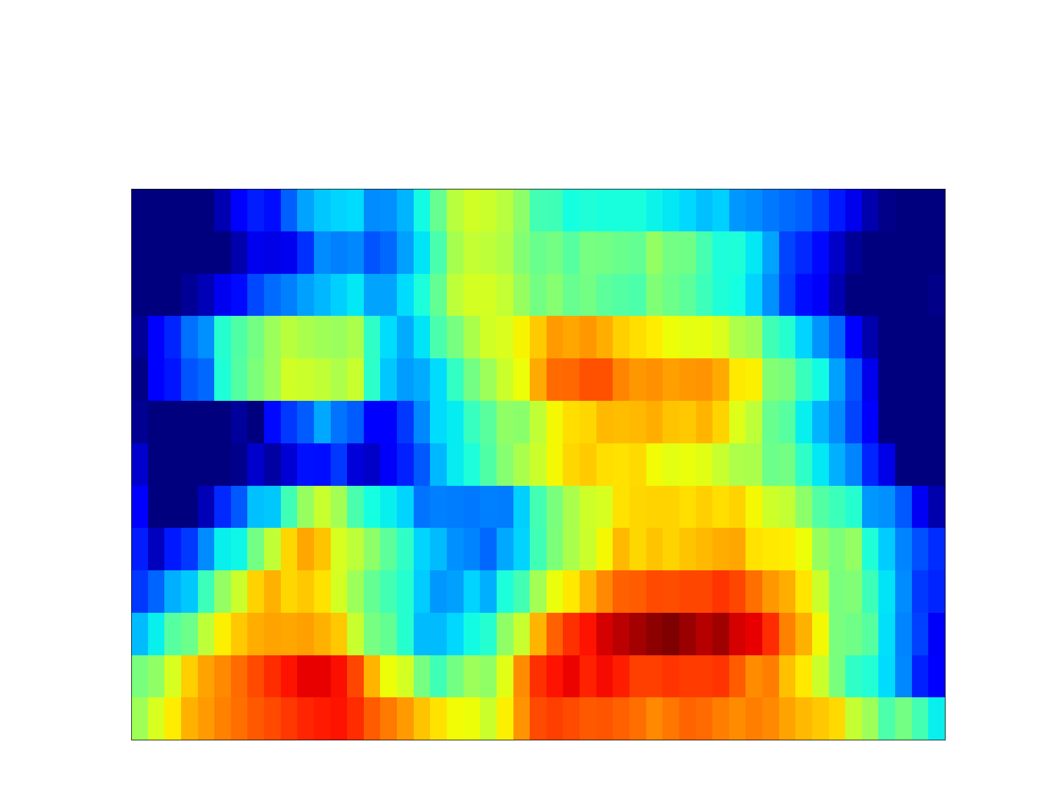
|
|
|
| Synthesized Spectrogram |
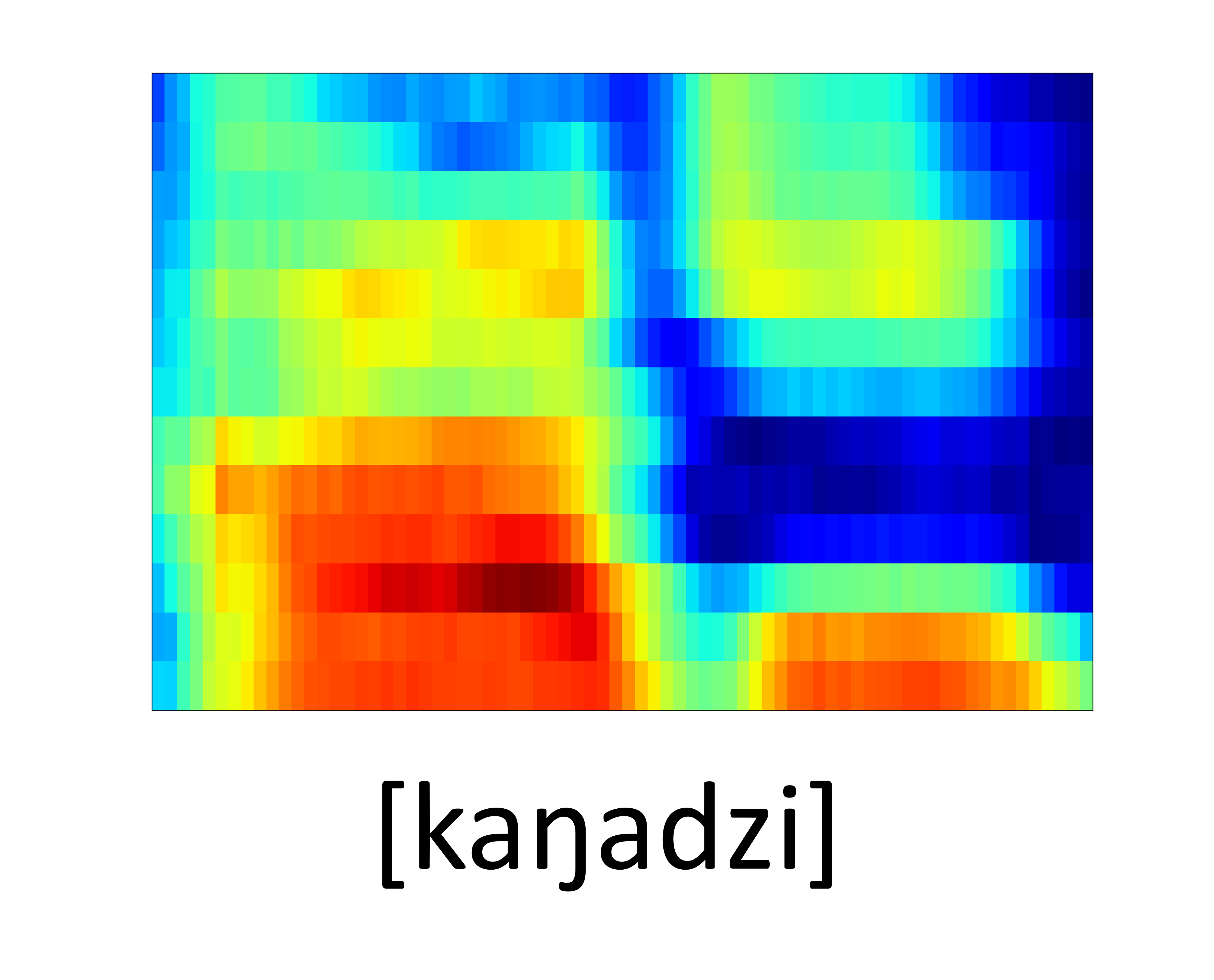
|
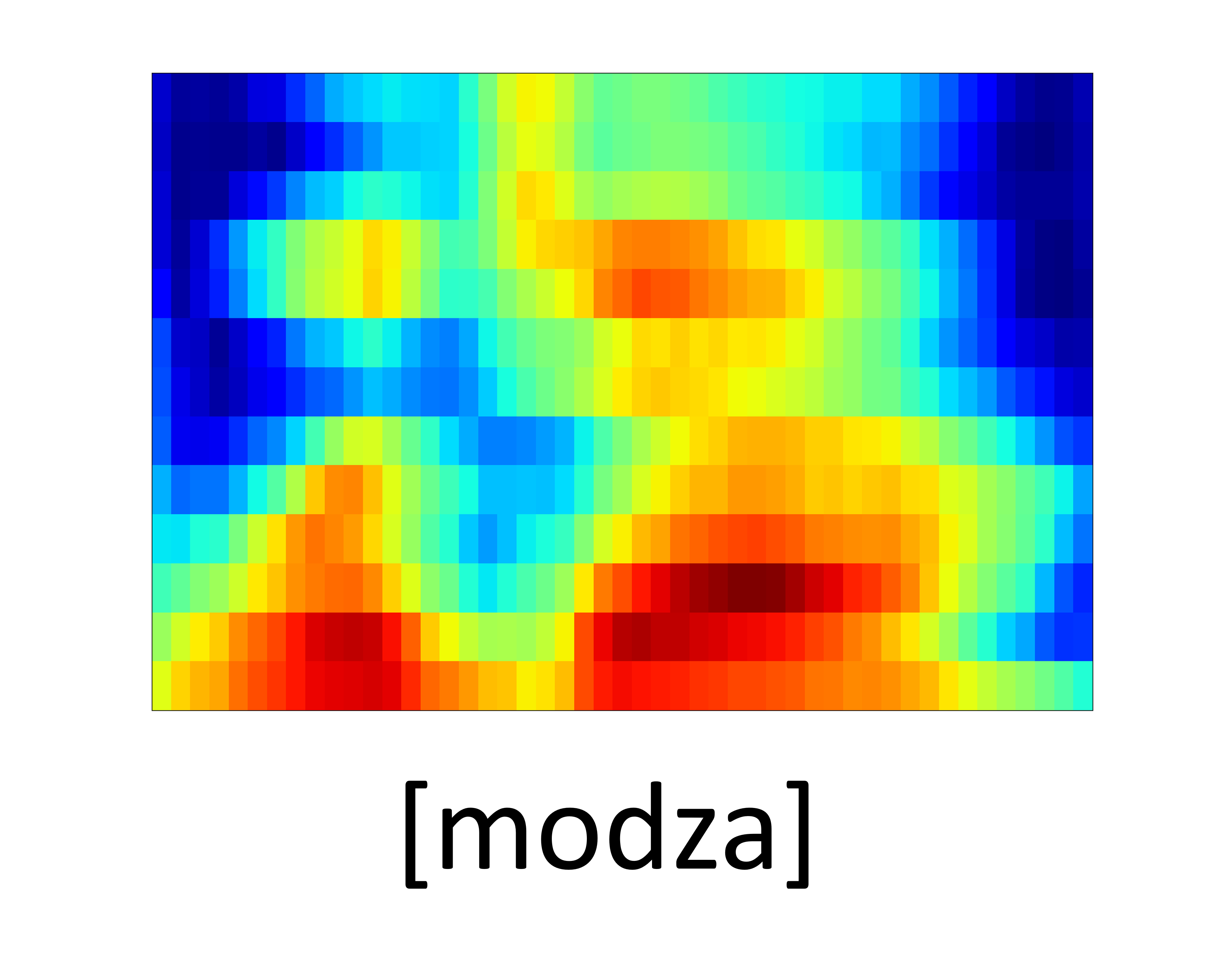
|
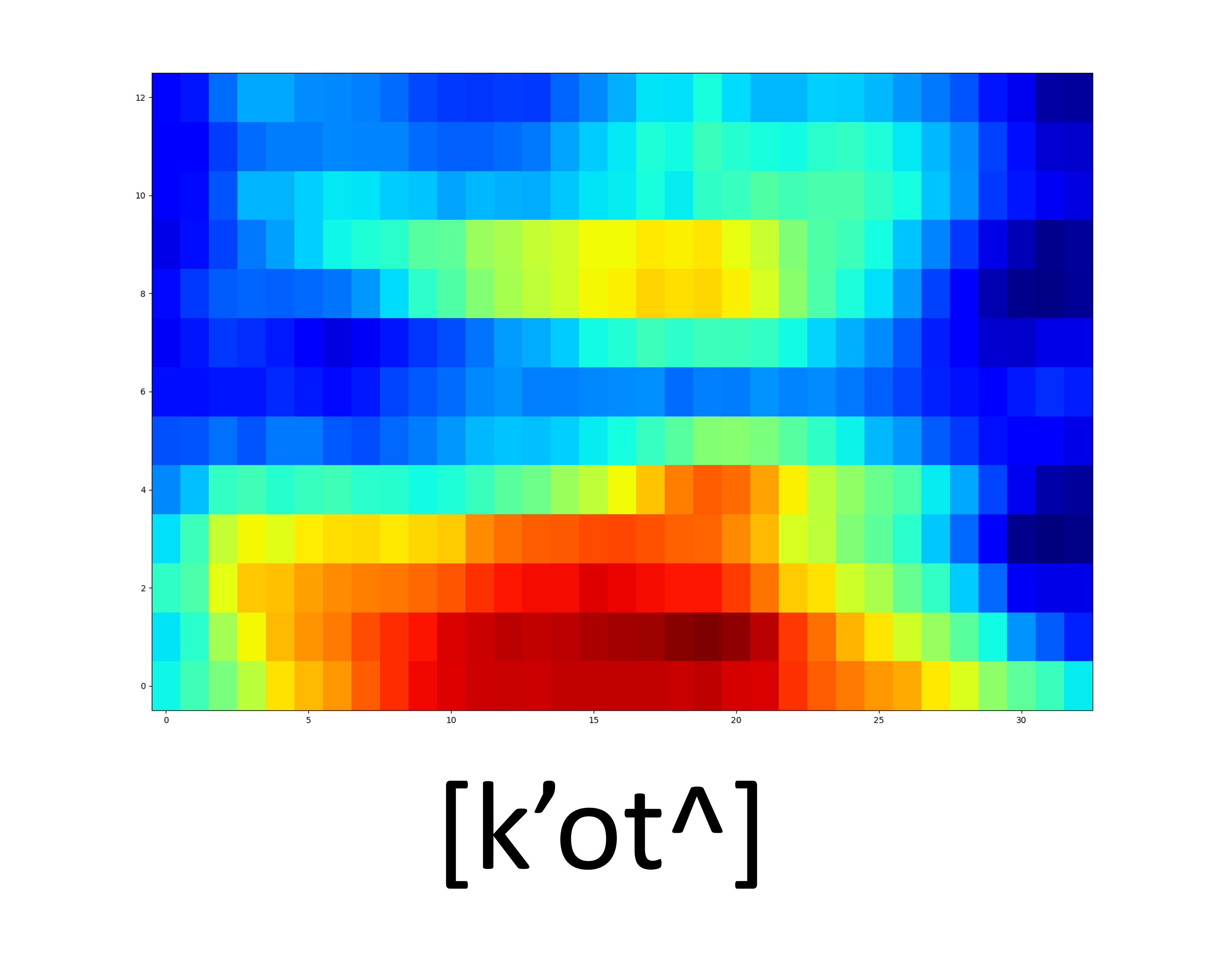
|
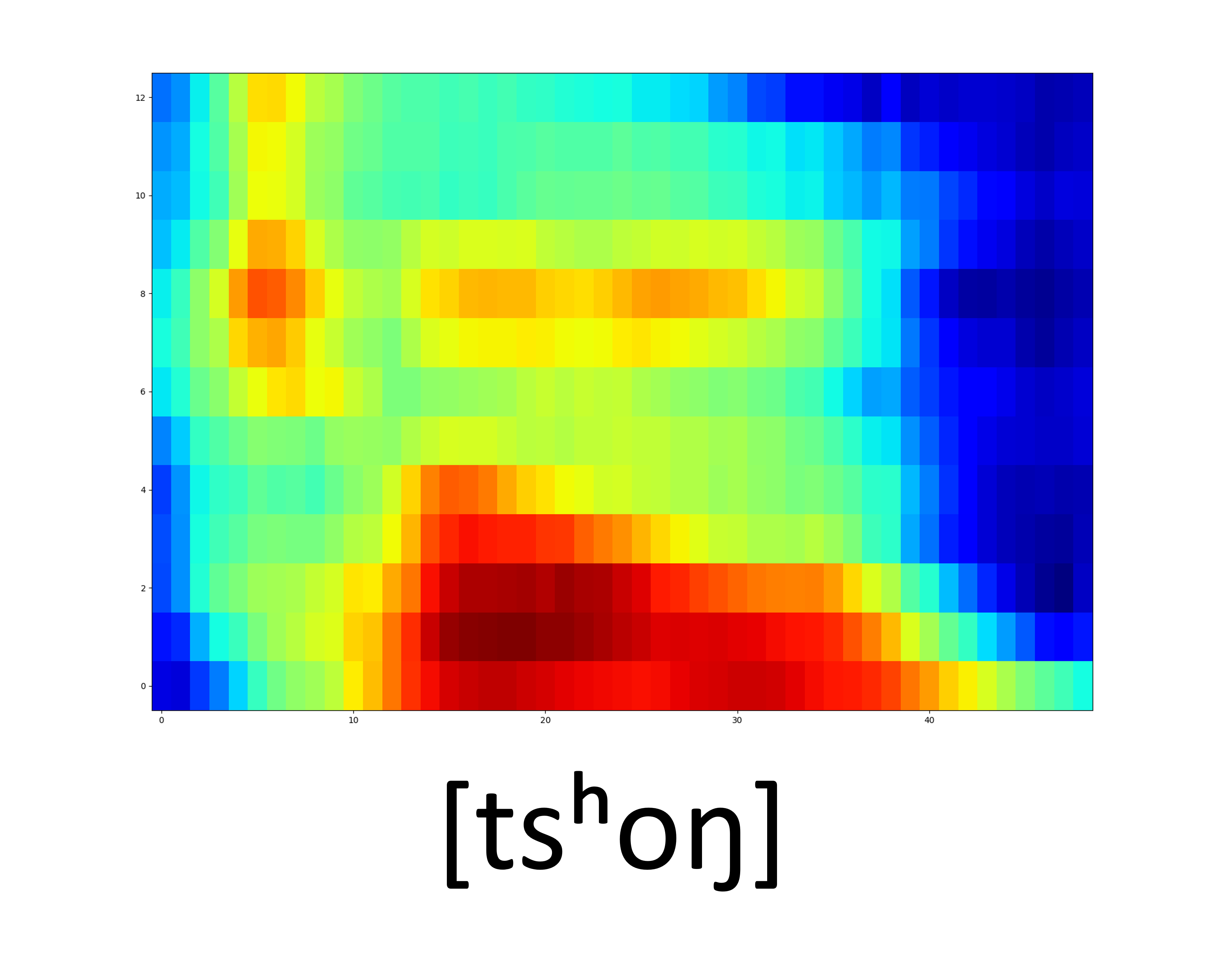
|
| GT | ||||
| GT (hifi-gan) | ||||
| Proposed |
Unseen samples - [sʰon]
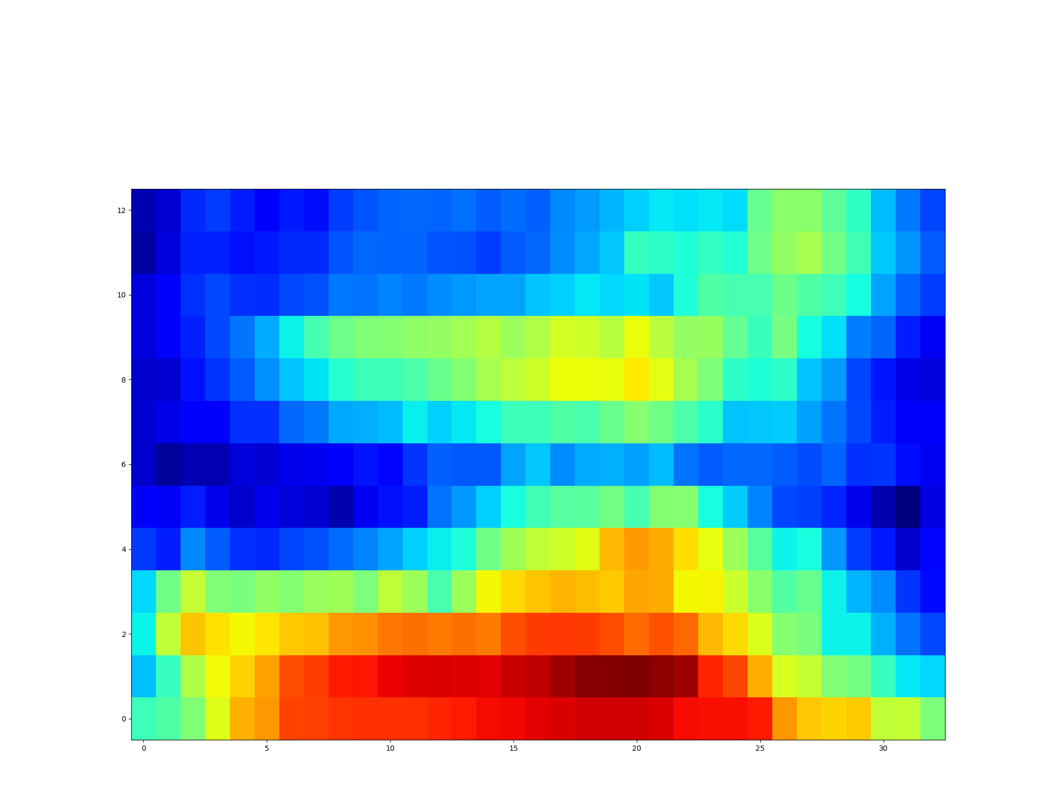
| GT Spectrogram |
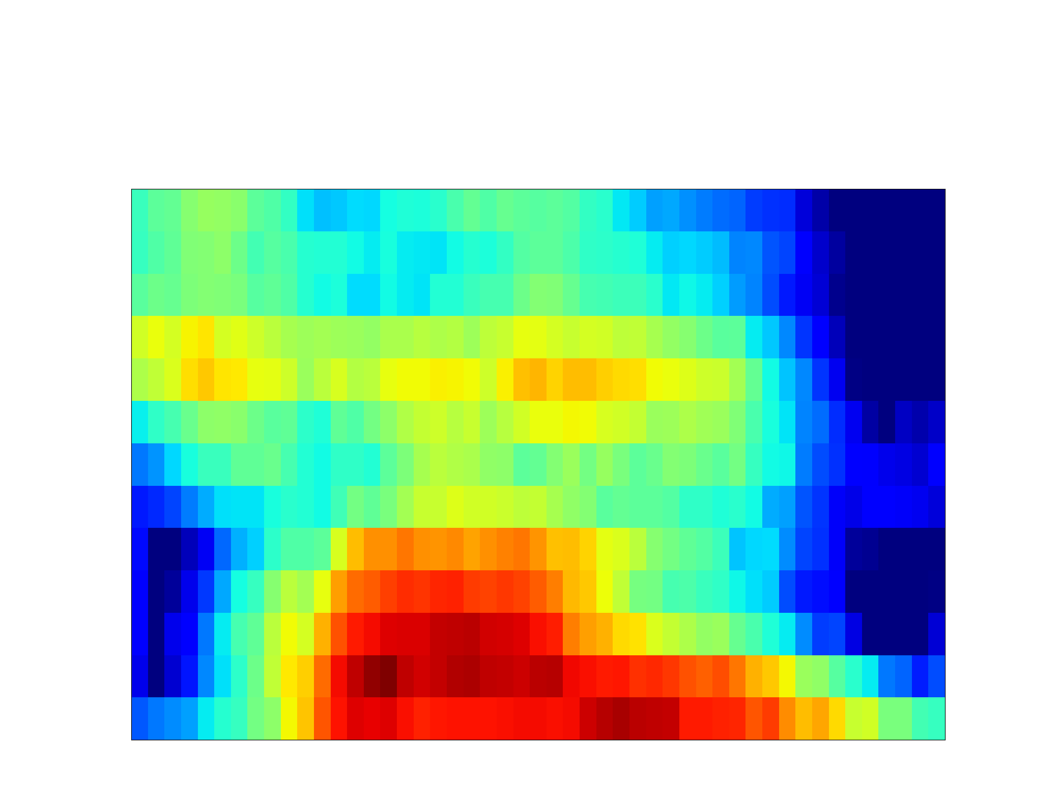
|
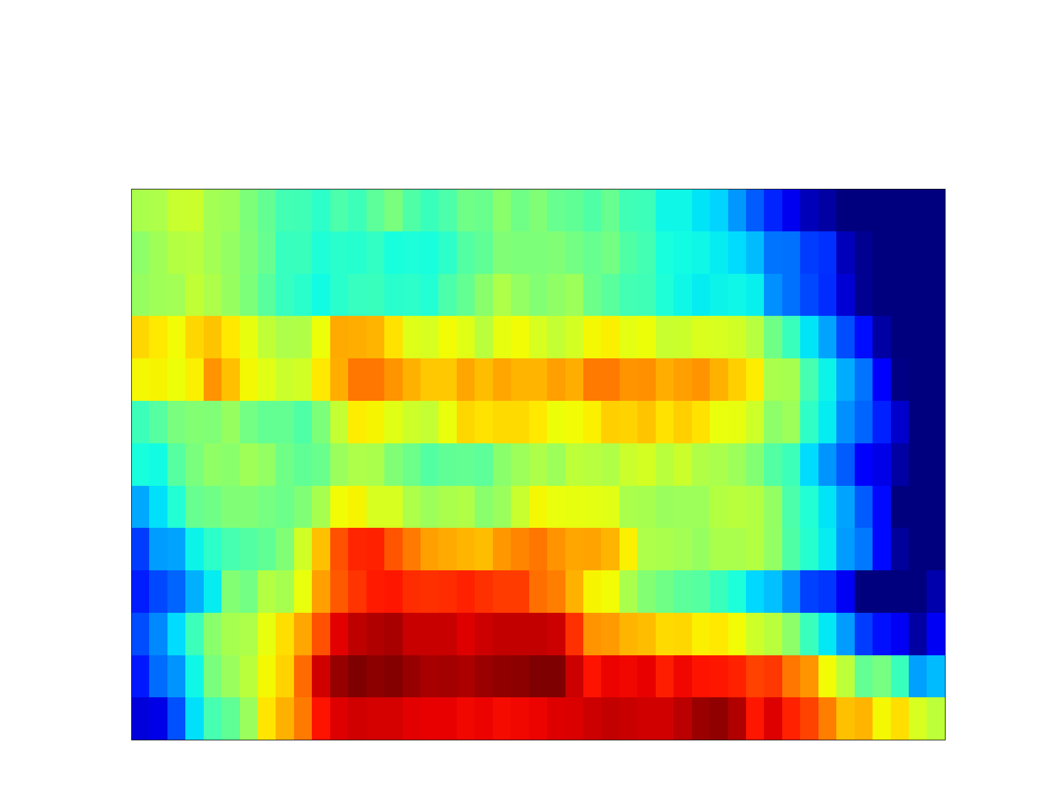
|
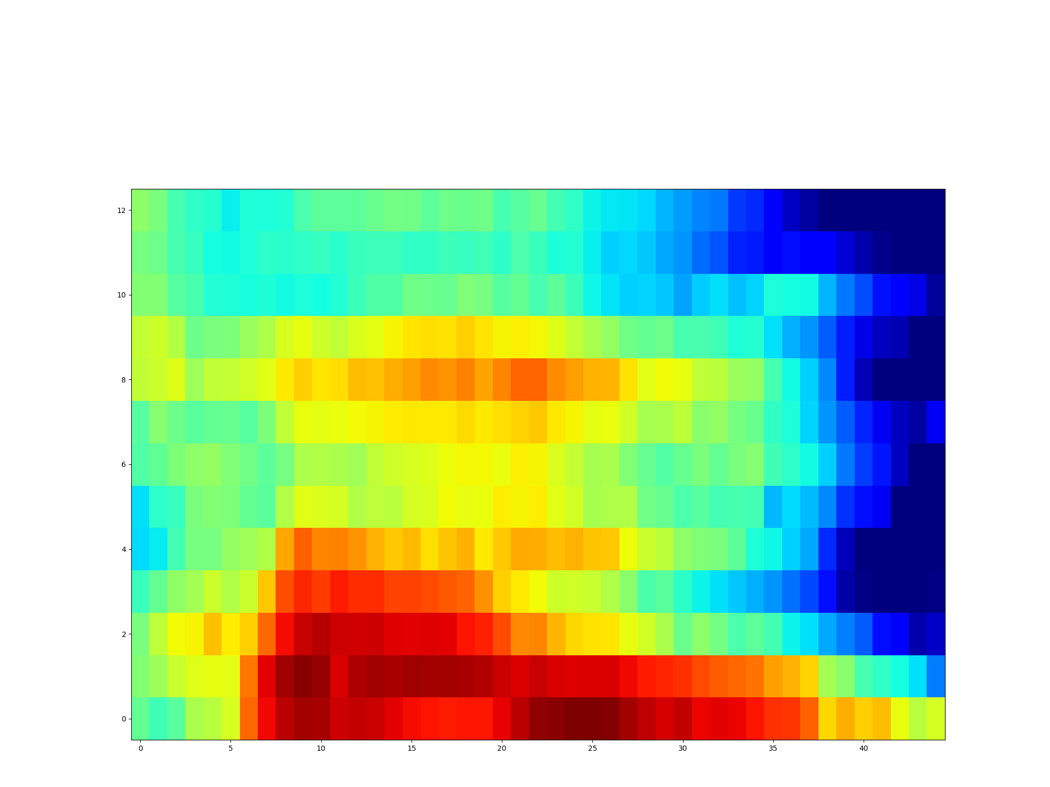
|
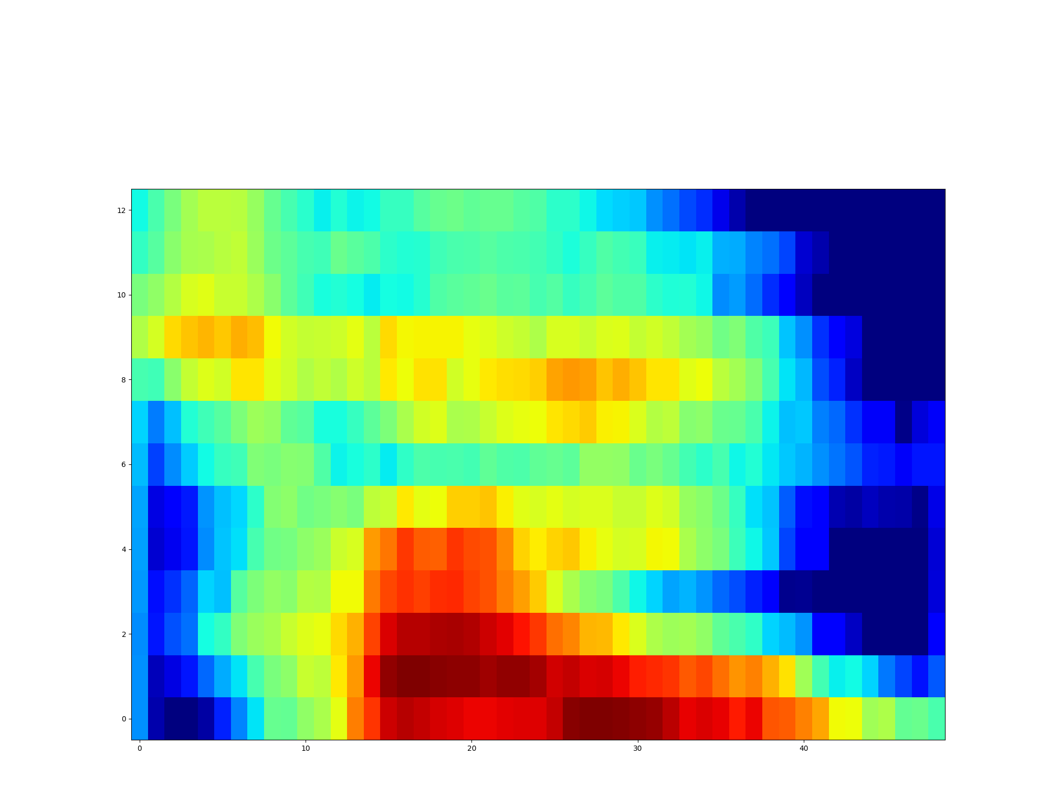
|
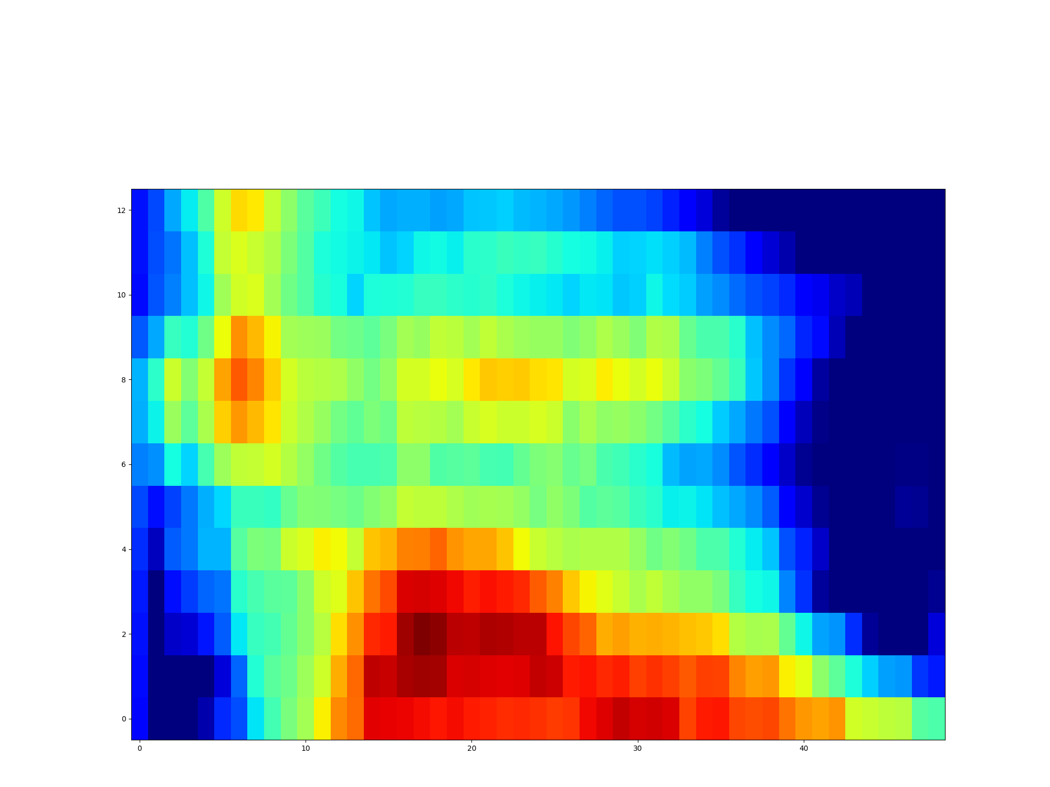
| Synthesized Spectrogram |
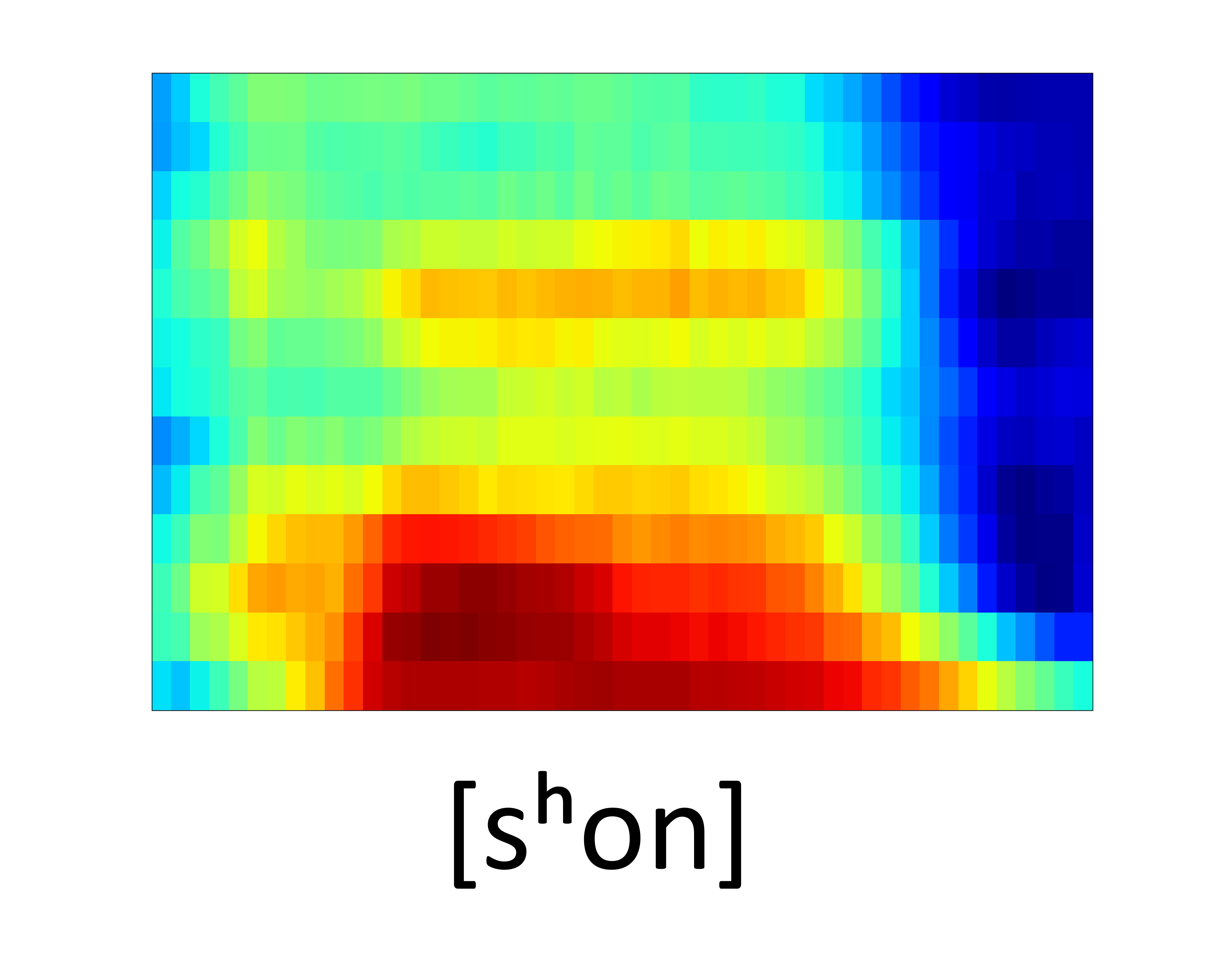
|
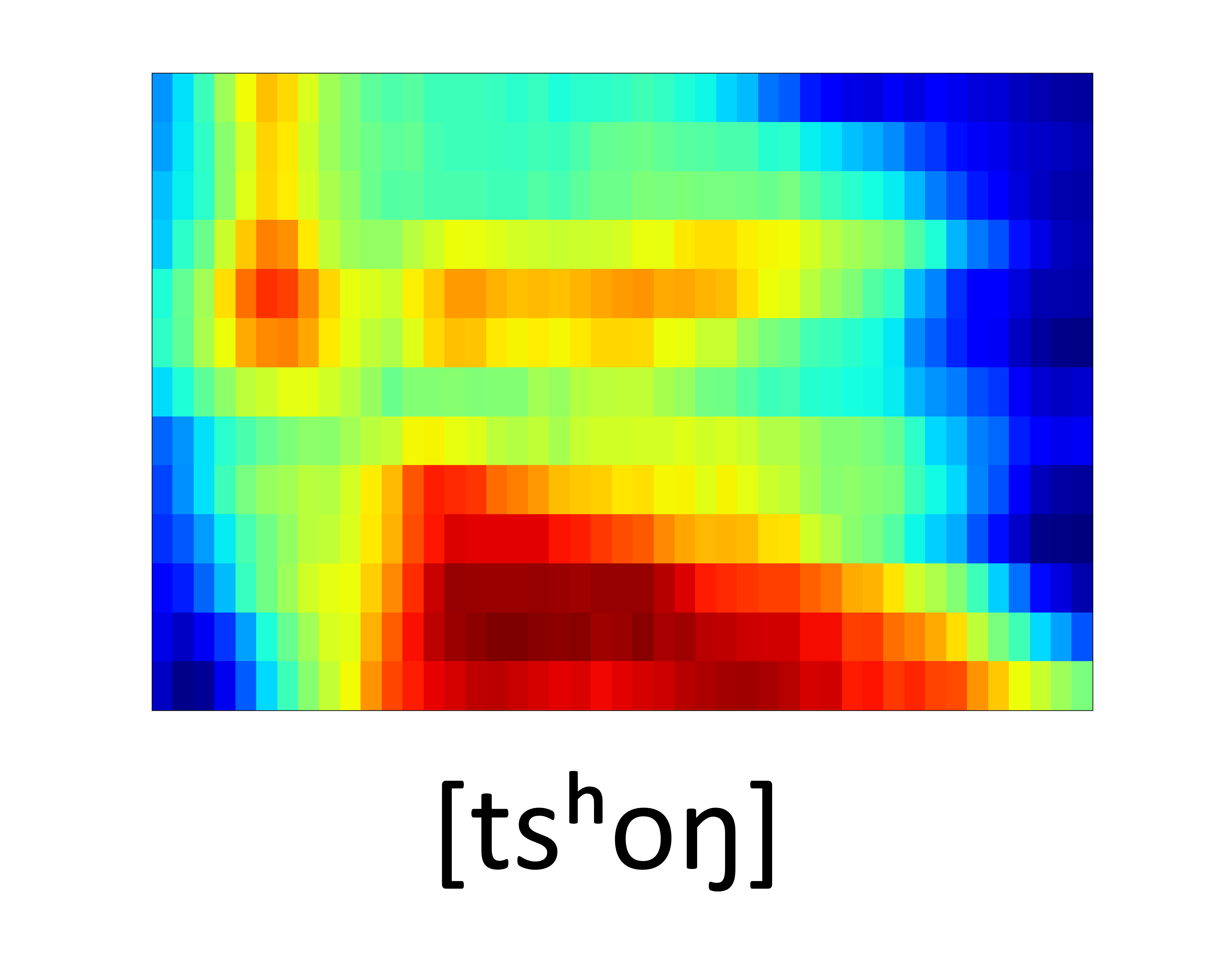
|
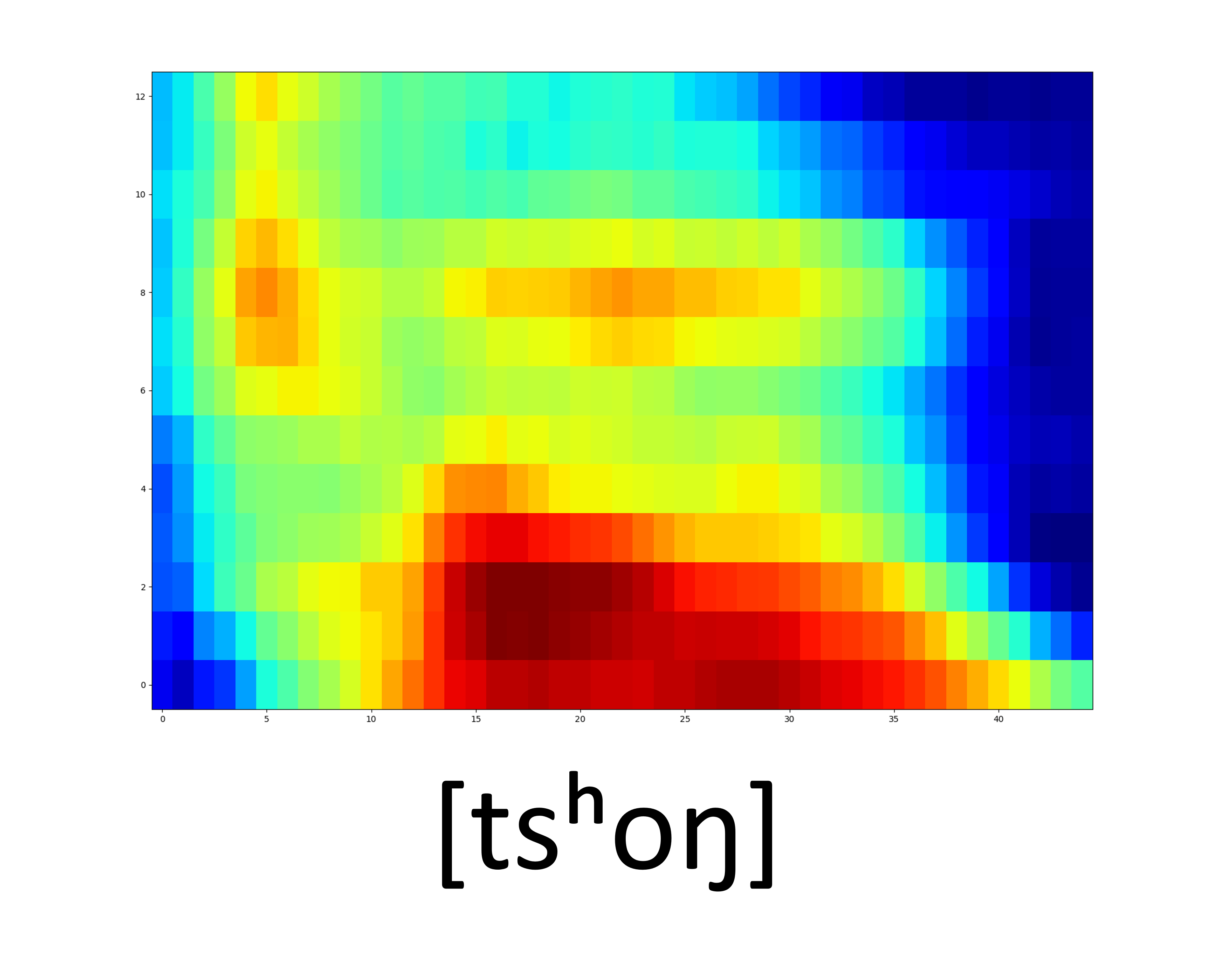
|
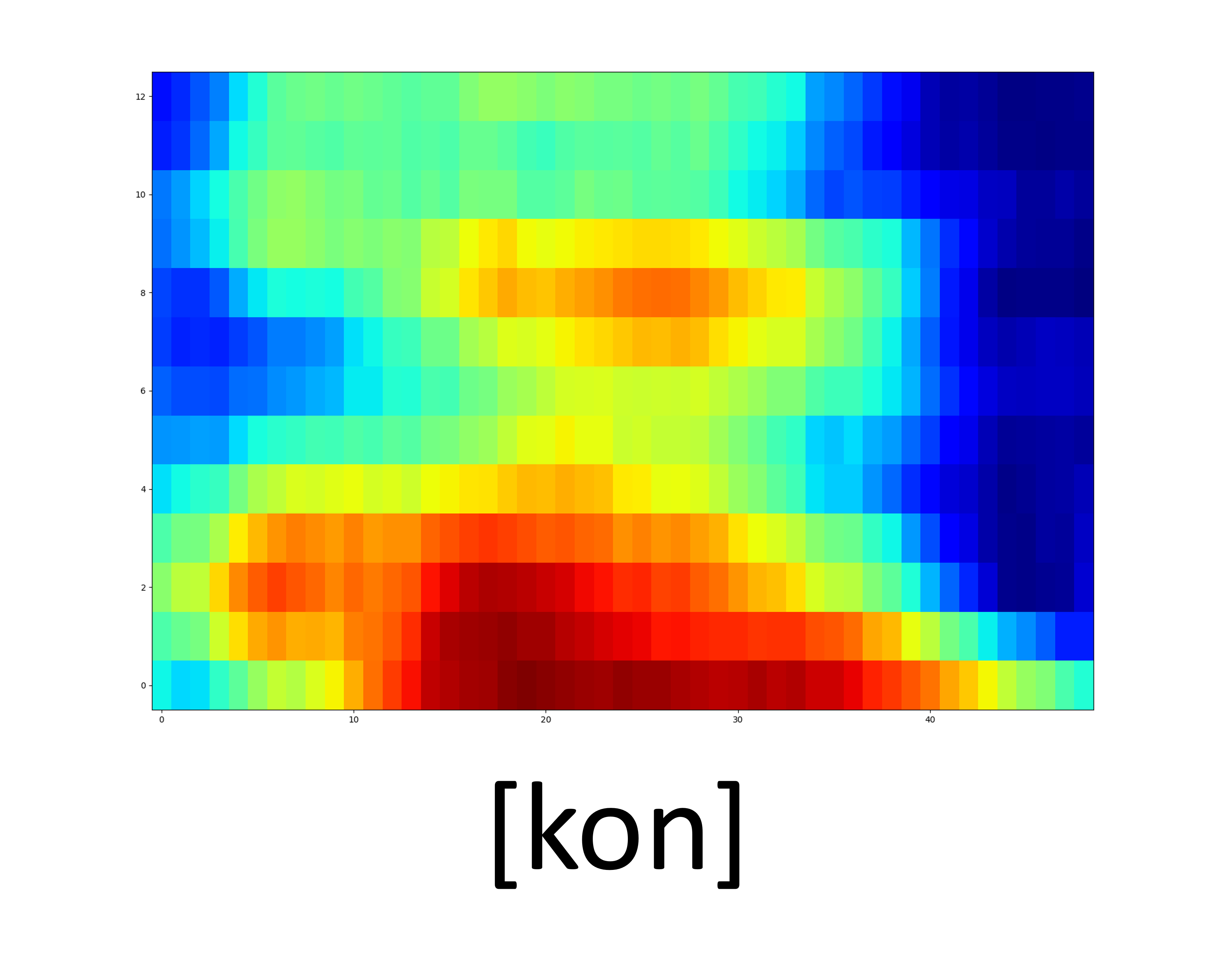
|
| GT | ||||
| GT (hifi-gan) | ||||
| Proposed |